type
status
date
slug
summary
tags
category
icon
password
1.概述
HDFS集群: 负责海量数据的储存,由三个部分所组成,分别为NameNode,DateNode,SecondaryNameNode.
<!--more-->
NameNode:NameNode是HDFS集群的主服务器,通常称为名称节点或者主节点。一但NameNode关闭,就无法访问Hadoop集群。NameNode主要以元数据的形式进行管理和存储,用于维护文件系统名称并管理客户端对文件的访问;NameNode记录对文件系统名称空间或其属性的任何更改操作;HDFS负责整个数据集群的管理,并且在配置文件中可以设置备份数量,这些信息都由NameNode存储。
DateNode:DataNode是HDFS集群中的从服务器,通常称为数据节点。文件系统存储文件的方式是将文件切分成多个数据块,这些数据块实际上是存储在DataNode节点中的,因此DataNode机器需要配置大量磁盘空间。它与NameNode保持不断的通信,DataNode在客户端或者NameNode的调度下,存储并检索数据块,对数据块进行创建、删除等操作,并且定期向NameNode发送所存储的数据块列表,每当DataNode启动时,它将负责把持有的数据块列表发送到NameNode机器中。
SecondaryNameNode:辅助NameNode,分担其工作量。比如定期合并Fsimage和Edits,并推送给NameNode,相当于NameNode的一个秘书。
2.安装要求
需要三台以上的Linux服务器,以及Java环境。(本次使用四台服务器来搭建)
3.配置静态IP
首先是先确定四台服务器的IP范围与主机名
主机 | IP |
NameNode | 192.168.106.128 |
SecondaryNameNode | 192.168.106.129 |
DataNode1 | 192.168.106.130 |
DataMode2 | 192.168.106.131 |
设置服务器IP:
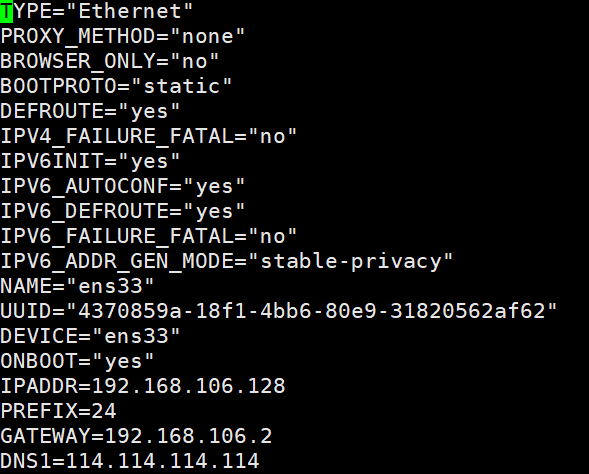
然后重启即可生效
其他三台服务器也是一样的操作
4.配置Java环境
首先安装好Filezilla文件上传工具便于jdk的上传
输入rz
解压jdk
将文件夹复制到/usr/local/下,并重命名为jdk8
将jdk添加到系统环境变量

立即生效
测试一下

出现这个说明Java环境已经配置好了

5.HDFS的搭建
- 上传Hadoop的压缩包到服务器
- 解压压缩包
- 将解压后的文件复制到/usr/loacl/下
- 将Hadoop添加到系统变量中
- 将以下内容添加到Java系统变量的下面
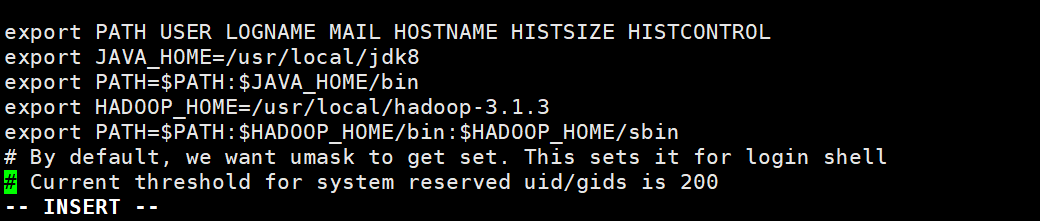
- 最后让系统变量生效
- 查看Hadoop是否安装完成

出现以上提示则说明安装完成
- 下面接着配置hadoop-env.sh,由于通过SSH远程启动进程的时候默认不会加载/etc/profile设置,JAVA_HOME变量就加载不到,需要手动指定。
- hadoop-env.sh文件在/usr/local/hadoop-3.1.3/etc/hadoop目录下
然后添加jdk的路径

- 配置core-site.xml
- 打开core-site.xml
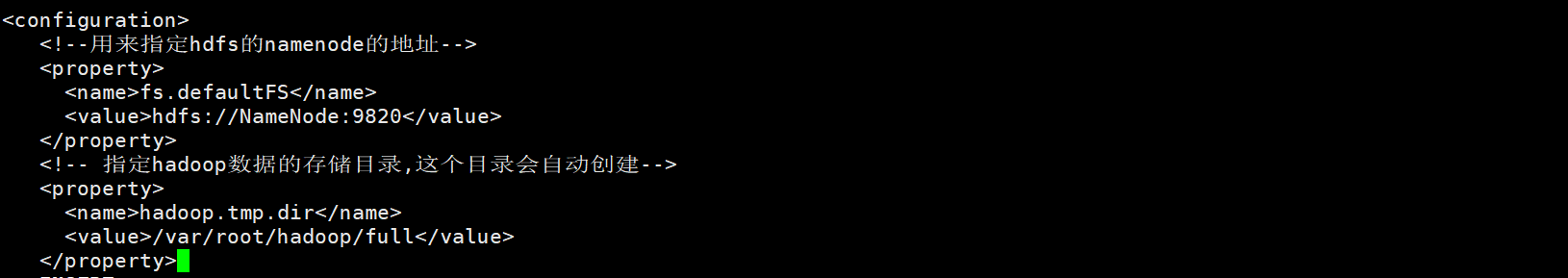
- 配置hdfs-site.xml
6.配置其他主机
- 关闭防火墙和禁用防火墙
- 使用vm直接克隆三台服务器,然后分别配置好主机名和IP
- 设置四台主机的免密登录 1.生成密钥(在xshell中可以批量执行)
2.将密钥拷贝到authorized_keys中
3.然后分别将密钥拷贝到四台机器上即可
- 设置使用root用户登录(四台机子上都执行)
- 修改主机名hostName(使用主机名来替代ip)
- 集群内主机的域名映射配置
可以通过域名访问IP
在header上,
vi /etc/hosts#将hosts文件拷贝到集群中的所有其他机器上
使配置立即生效
workers**配置**
加入所有的节点
7.启动hdfs
start-dfs.sh以上用到的文件