type
status
date
slug
summary
tags
category
icon
password
使用requests实现下载喜马拉雅音频
分析音频地址
首先任意打开一个专辑
然后按f12打开开发者工具,找到
Network
需求是要下载专辑中的音频,音频是属于媒体文件,所以点开
Media
可以看到现在是什么都没有的状态,播放一个音频,可以发现已经抓取到了一个音频文件
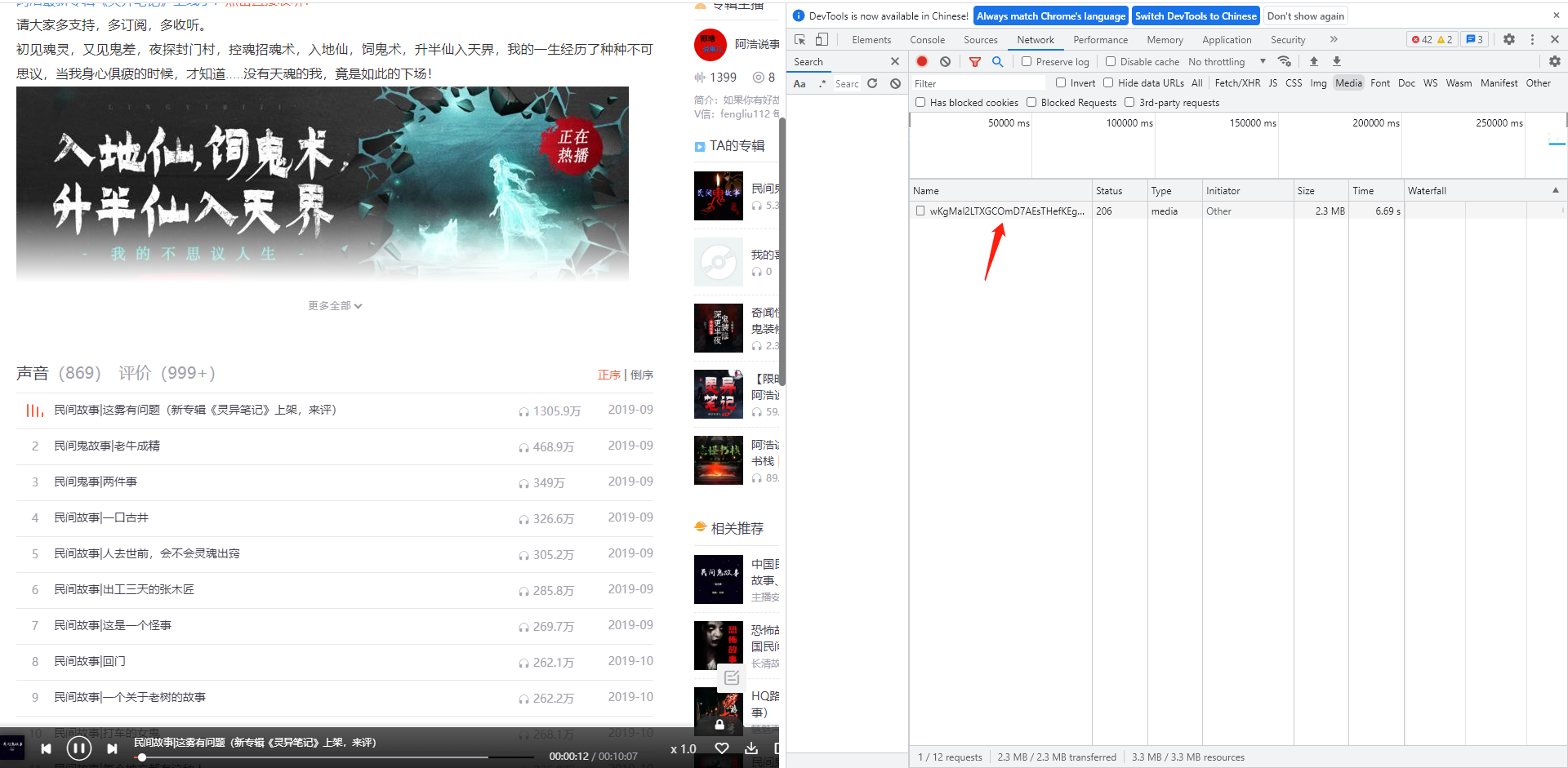
通过查看请求url可以看到这是一个m4a的音频文件
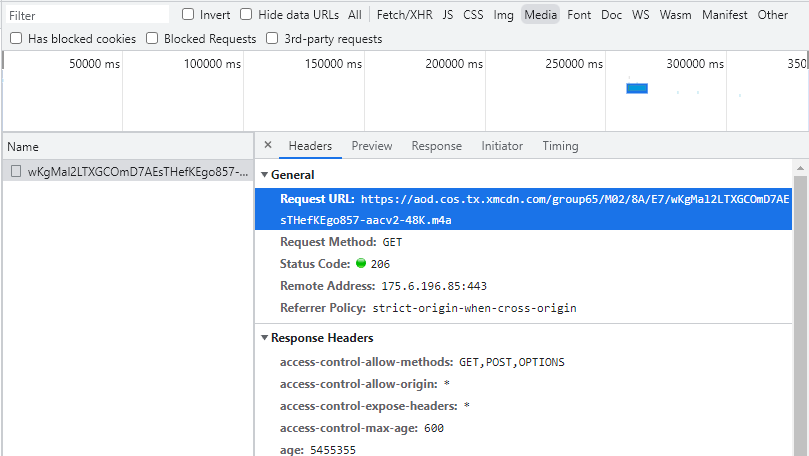
复制这个链接到另外一个窗口,可以知道这是一个音频链接,由于每个音频都是独一无二的,所以链接也必定是独一无二的,复制链接在开发者工具中搜索一下,可以发现这个链接是在一个链接请求中得到的
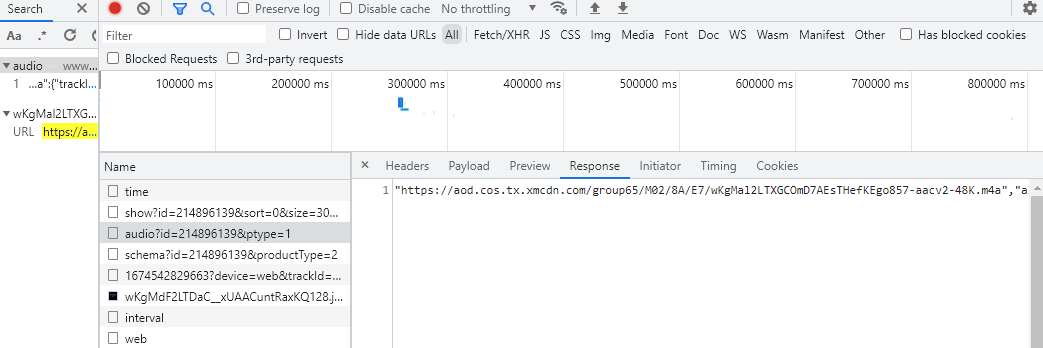
查看请求头
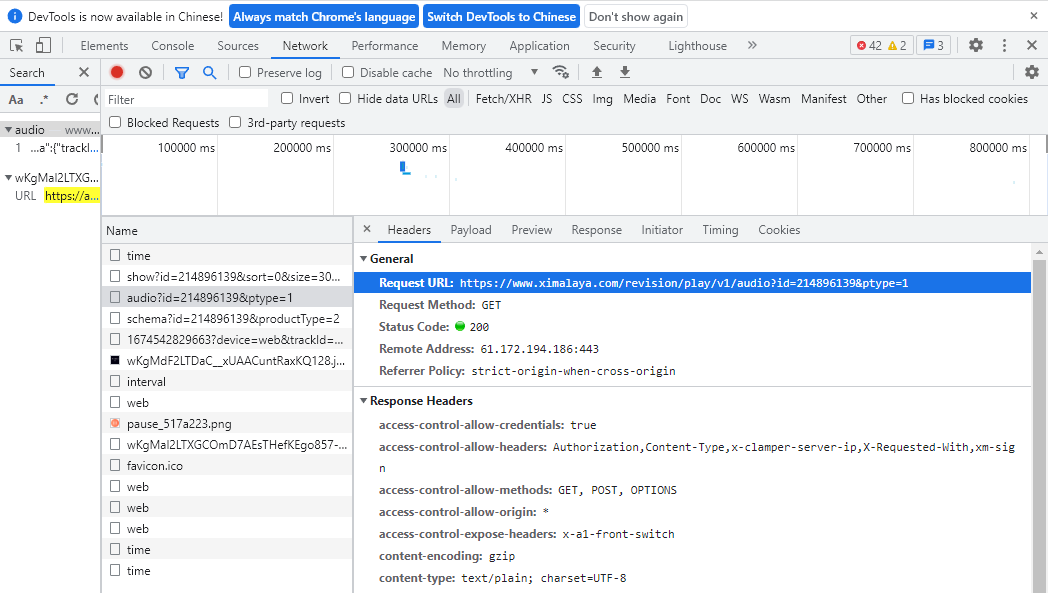
复制这个
Request URL,写下以下代码可以得到这样一个结果

访问字典中的元素,然后我们就得到这么一个链接

通过以下代码就可以下载文件
批量获取整个网页播放地址
在上一步已经获得了一个音频的请求地址:
url = 'https://www.ximalaya.com/revision/play/v1/audio?id=214896139&ptype=1',可以知道这个音频id是214896139,所以需要去获取每个不同的id。复制专辑首页的地址
https://www.ximalaya.com/album/29535750, 通过开发者工具可以知道请求方式是get
然后完成一个请求,搜索
音频id可以得到以下结果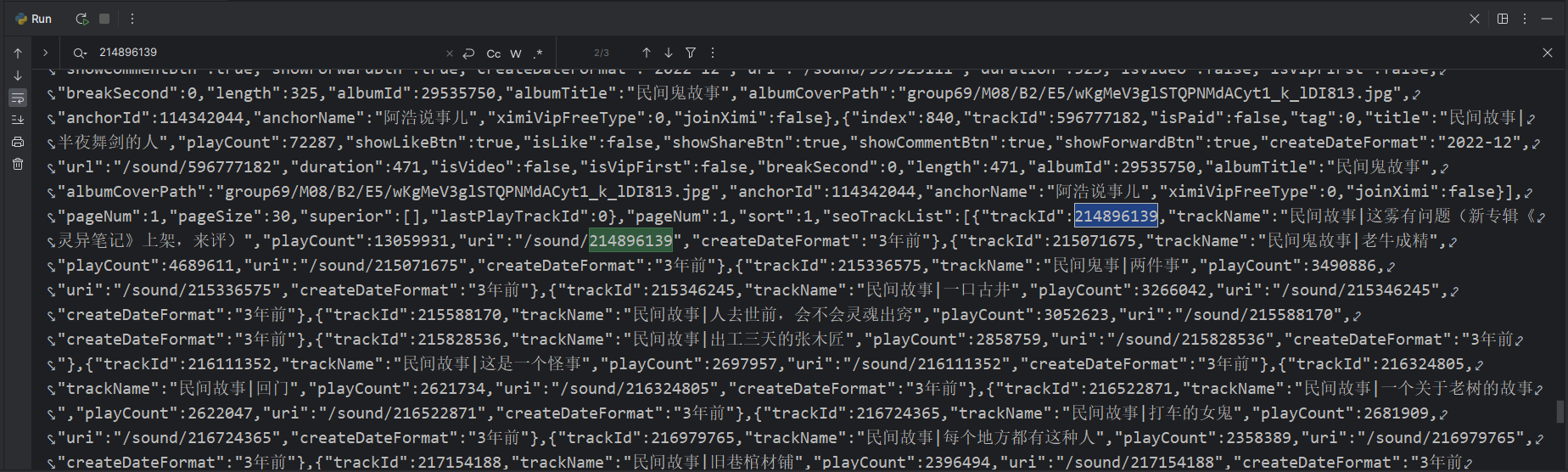
接着观察可以知道
trackId是音频的idtrackName是音频的名字。然后我们通过一个简单的正则表达式获取这些数据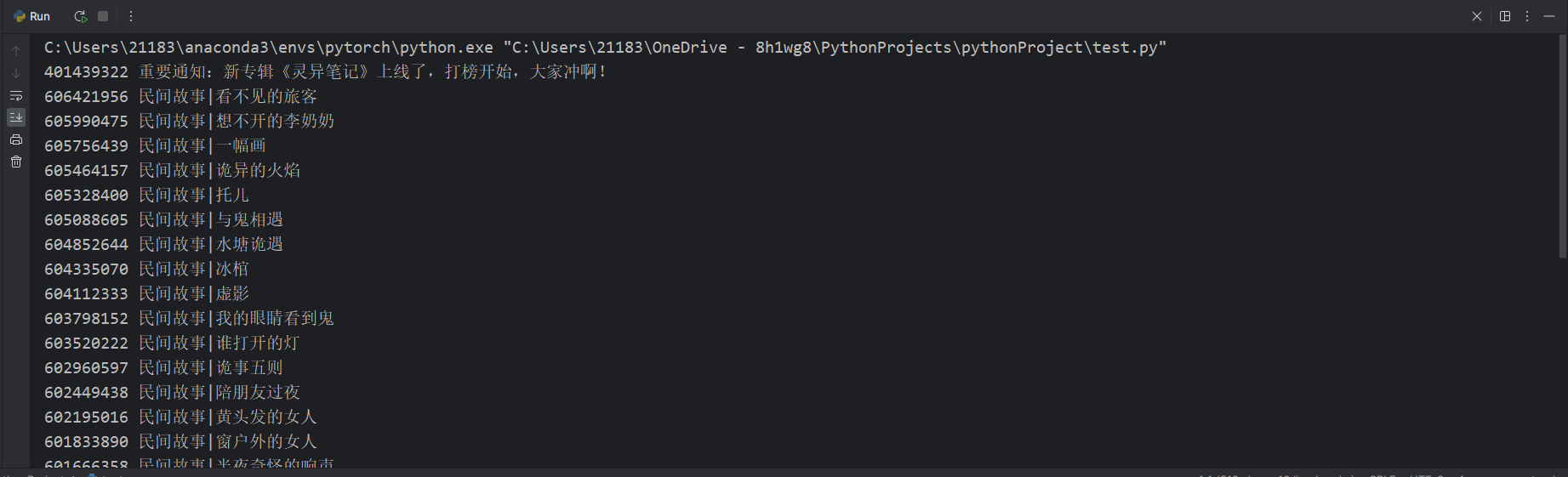
这样我们获取的id和文件名,但是这里只有30个,并不是总的内容
获取整个专辑地址
继续查看专辑页面,可以发现一页目录正好是30个,其他的需要翻页,那就通过抓包工具看看是发送了什么才首先翻页的
点击第二页可以发现是这个
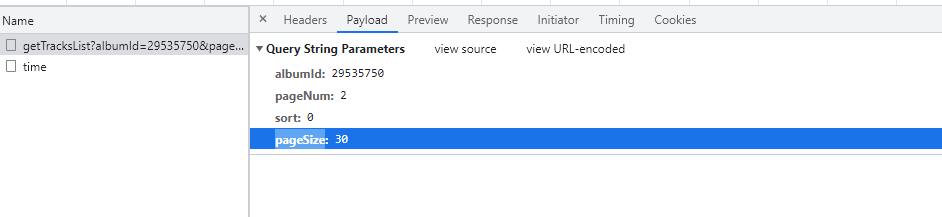
url=https://www.ximalaya.com/revision/album/v1/getTracksList?albumId=29535750&pageNum=2&sort=0&pageSize=30,请求方式是get,我们知道get请求是将要请求的数据放在url中,点开Payload,发现有以下对于关系albumId: | 专辑编号 |
pageNum | 页码 |
sort | 正序还是逆序 |
pageSize | 一页中目录有多少 |
当然,这些东西可能不能一下就理解,由于
get的请求在url中,你可以通过修改url中的参数查看来得到以上结果。得到以上内容,我们就可以通过修改上面的参数来获取不同专辑,不同页码的目录了。
到这里,基本上就可以得到所有的专辑了,但是,我们不知道专辑中有多少页,所以不能完整的下载所有的音频,继续查看开发者工具中的
Response可以看到这个
data里面有一个key为trackTotalCount的参数,正好是我们的总集数,我们就可以通过向上取整得到需要循环多少次。完整代码
整理一下可以得到以下完整代码